Detecting influenza A virus antigenicity with density-based algorithms
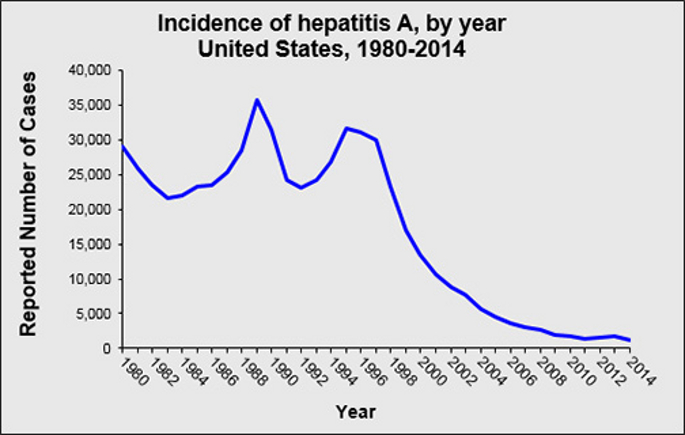
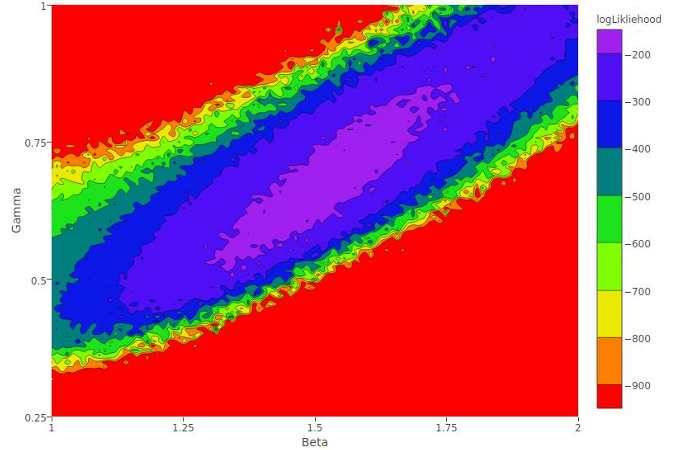
Sofia McDonough, a student from Florida State University, worked with Dr. Pej Rohani & Dr. Alpha Forna on density-based algorithms for detecting influenza A virus. Abstract: Influenza A H3N2 viruses mutate over time, leading to different antigenic variants. Viruses that elicit a similar immune response are considered to be part of the same antigenic cluster. It